
Metal Quantized Attention: pulling M5 Max ahead with Int8 matrix multiplication
M5 Max is the biggest AI performance jump we have seen on Apple Silicon. Our latest release pushes real-world performance further with Metal Quantized Attention and fused Int8 matrix multiplication.

Release of the M5 Max generated a great deal of goodwill in the AI community. We measured a 3.3× speed-up over the M4 Max out of the box, a level of performance we have not seen before on Apple Silicon.
At the same time, if you look at datasheets of their direct competitors, especially for the RTX 5080 Mobile, the picture is more nuanced. For AI workloads such as LLM prefilling and image generation, the RTX 5080 Mobile still advertises roughly 320 TFLOPs of peak compute. By comparison, our most efficient FP16 matrix multiplication shader on the M5 Max delivers about 60 TFLOPs. Part of that gap is a necessary trade-off for a thinner, quieter, and more elegant design. Another part is that the advertised ~320 TFLOPs figure for the RTX 5080 Mobile is based on FP8 matrix multiplication, which is a lower-precision format than FP16.
With Draw Things v1.20260330.0, we are releasing Metal Quantized Attention to help close that gap. In real-world AI workloads such as image and video generation, our shaders now regularly reach around 110 TFLOPs on M5 Max. That brings Apple Silicon closer than ever to the RTX 5080 Mobile in practical terms, assuming thermal limits allow that device to sustain its peak performance.
Metal Quantized Attention
Metal Quantized Attention is our implementation of a low-bit attention operator written in Metal compute shaders. It takes FP16 or BF16 query, key, and value tensors, performs online quantization to Int8, and carries out the attention computation almost entirely in Int8. Queries and keys use row-group-wise scale quantization, while values use row-wise affine quantization.
In practice, this delivers a 1.24× to 1.41× speed-up over our Metal Flash Attention shader, which is already our fastest attention shader on M5 with Neural Accelerators.
Int8 Matrix Multiplication with Row-wise Scales
We also did a careful analysis of the quality impact of Int8 math with row-wise scales and found it to be an acceptable trade-off relative to the full-precision base model. In our testing, it is comparable to, and often better than, our 6-bit palettized quantization scheme.
The fused shader handles row-wise dynamic activation quantization, Int8-to-Int8 matrix multiplication, and post-accumulation dequantization together. End to end, our dynamic quantization + Int8 matrix multiplication + dequantization fused kernel is about 1.61× to 1.87× faster than our FP16 baseline.
End-to-End Speed-up
In v1.20260330.0, we enabled Metal Quantized Attention by default on M5 devices. You can still turn it off in Machine Settings. This feature applies across all models. Int8 matrix multiplication applies only to the 8-bit S models we recently added.
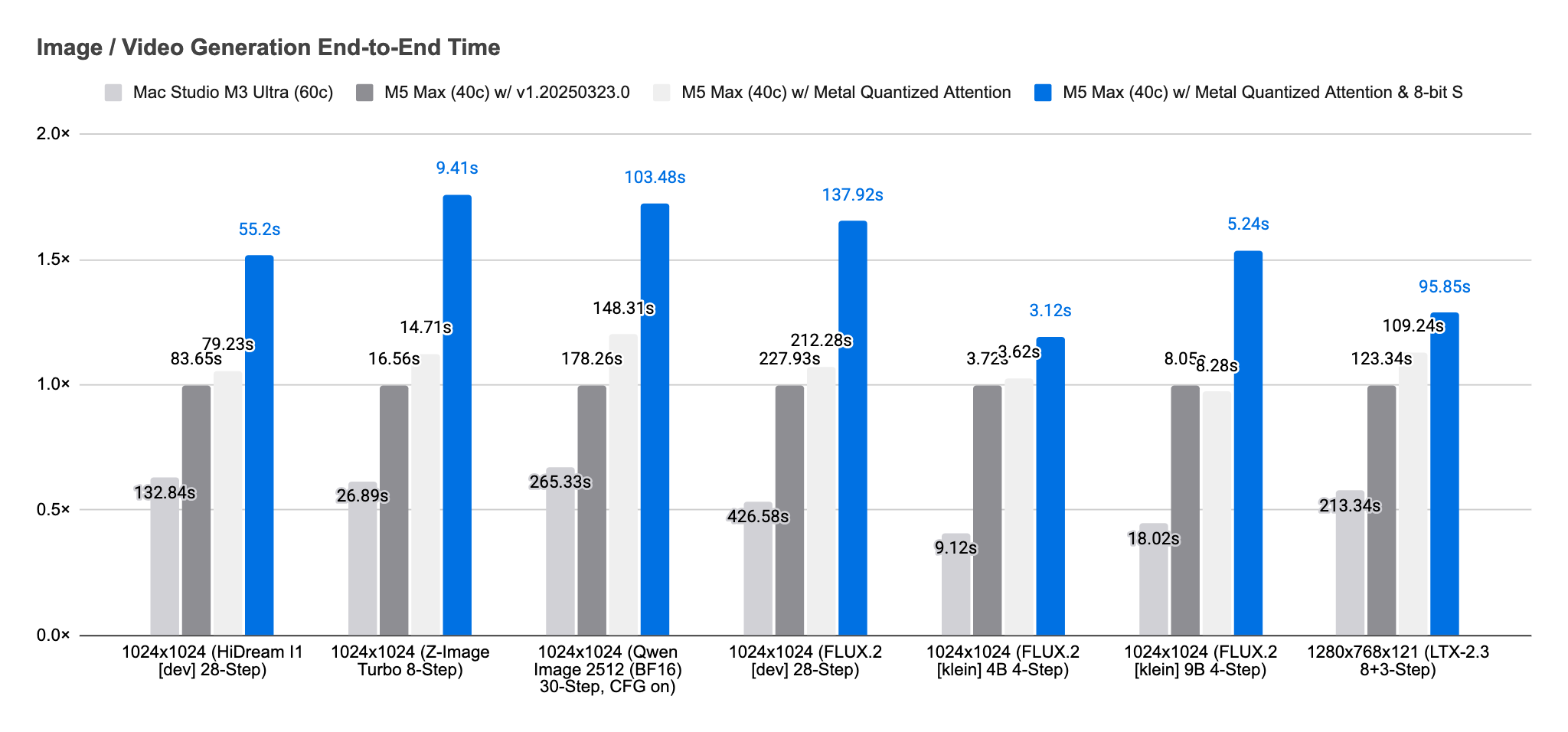
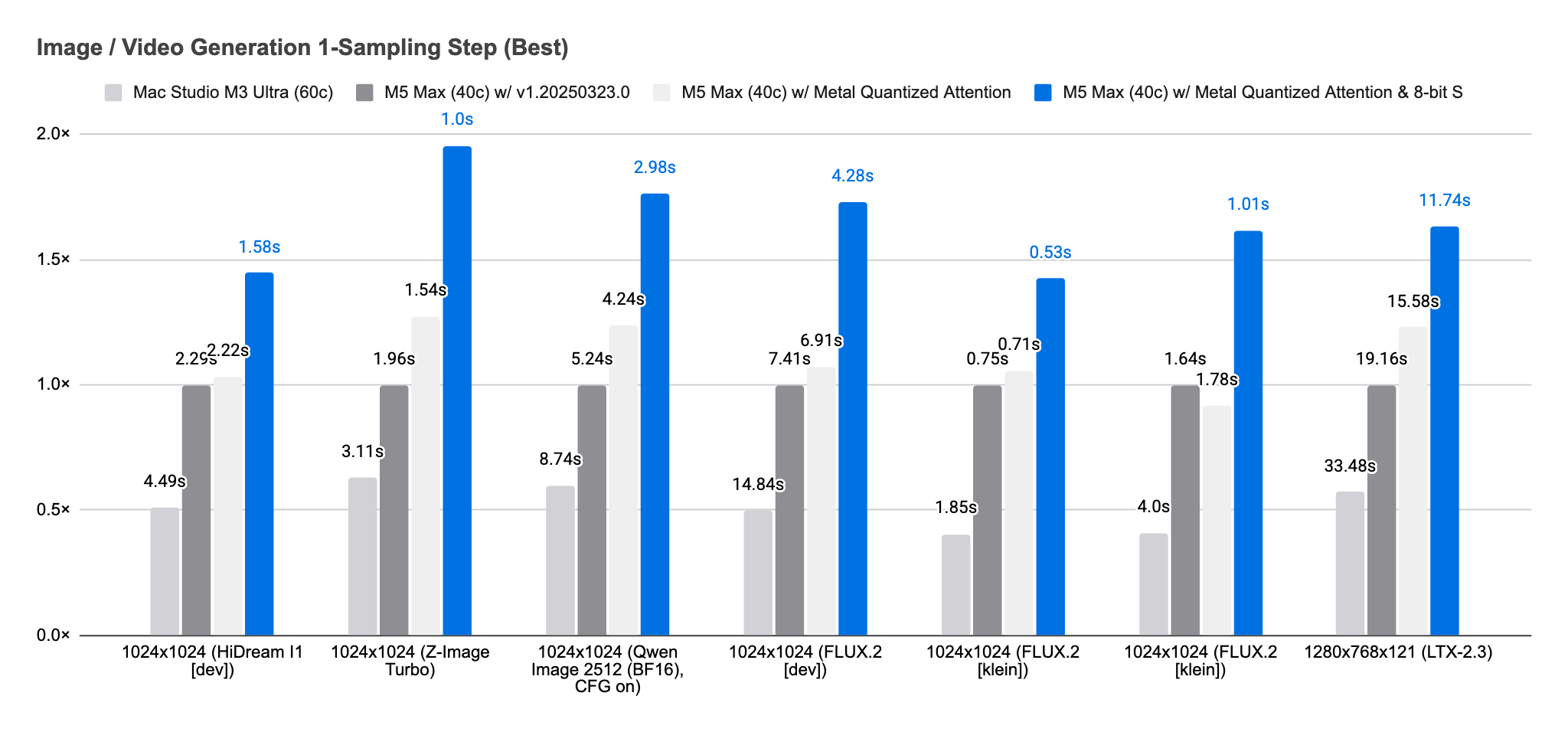
End to end, these changes deliver a 1.19× to 1.76× speed-up over v1.20260323.0. For a single sampling step alone, excluding model loading, text encoding, image decoding, and model lowering, the improvement ranges from 1.43× to 1.95×.
Pulling Ahead over Other Implementations
Metal Quantized Attention and fused Int8 matrix multiplication push our implementation well ahead of other Apple Silicon implementations for the same task. In our testing, we have seen performance ranging from 1.24× to 2.57× faster than the next best alternatives, including mflux, Ollama, iris.c, and mlx-video.
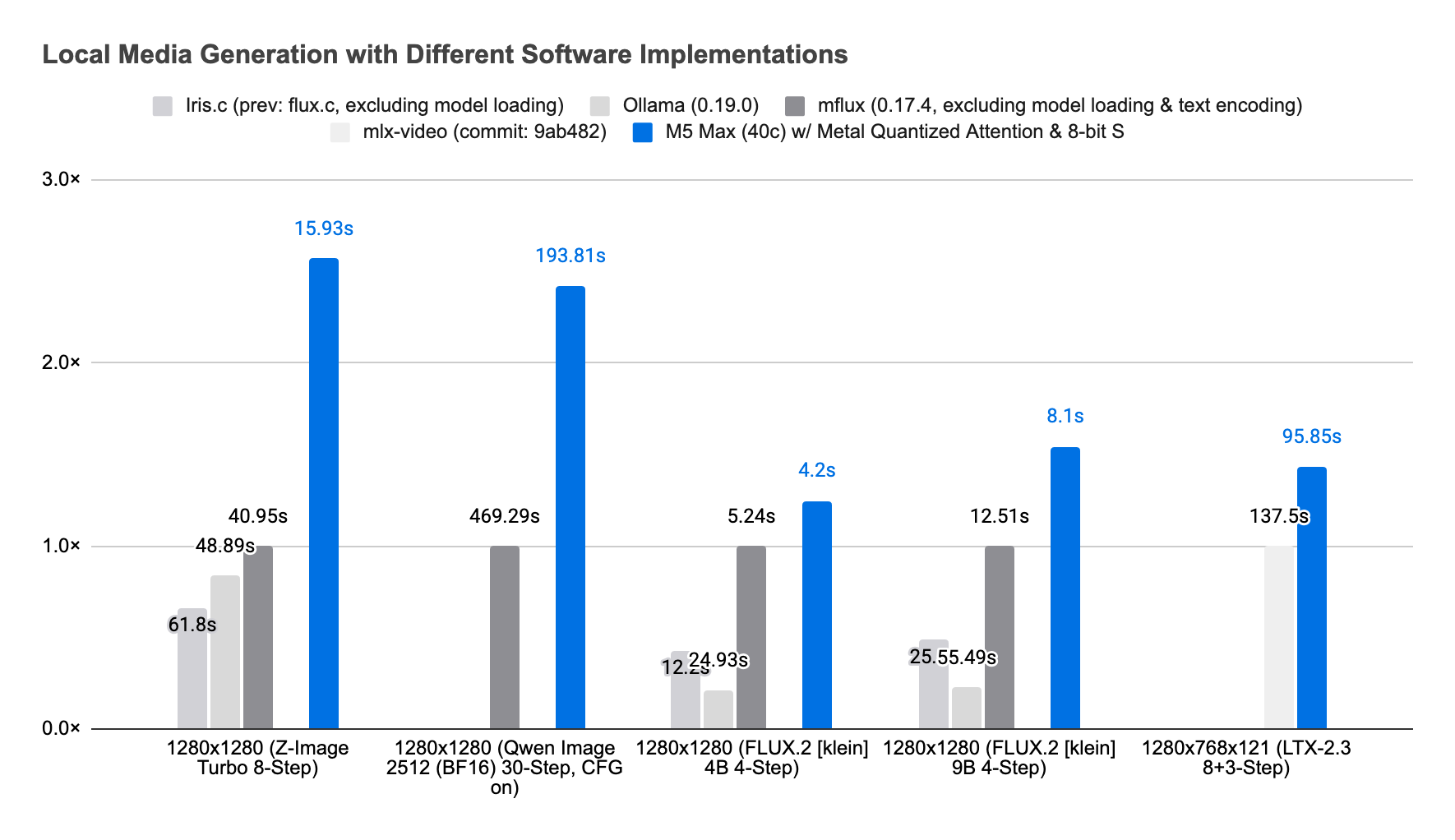
As always, our shader work is publicly available under the FreeBSD 3-Clause License, and our inference stack is publicly available under the LGPLv3 license. For local media generation tasks with your agent, you can also use draw-things-cli.
Can you add M4 Max results ? Thanks